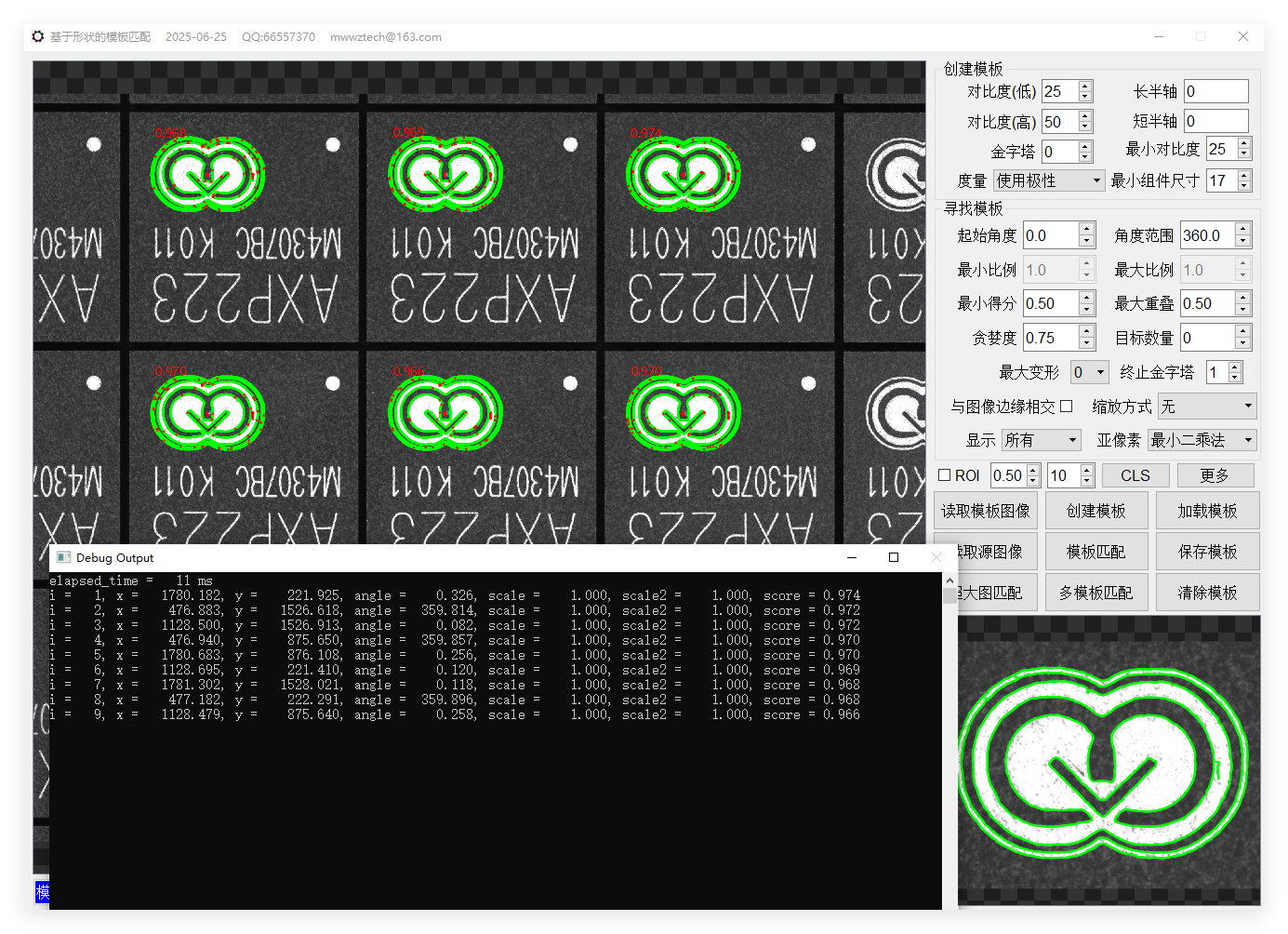
对halcon形状匹配算法的一点分析
halcon的形状匹配算法执行速度极快,以下面这张图为例,分辨率:2448×2048(500万像素),角度范围:360°,亚像素:least_squares,halcon仅用了10ms左右,如果在程序中调用,最短仅需5 - 6ms,halcon是如何做到的呢?其底层运用了哪些技术与方法呢?
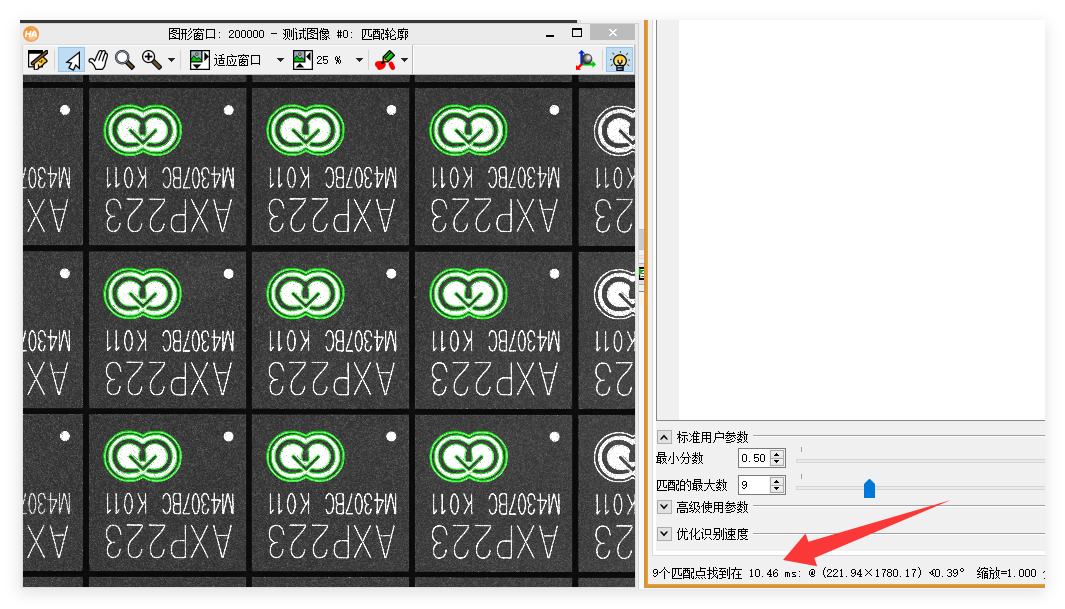
抱着上面的疑问,我下载了intel vtune profiler,这是一个高性能分析工具,可以做热点分析、微架构分析、并行性分析、内存与I/O分析。然后将halcon的匹配过程封装为一个C++函数,在一个线程中循环运行5000次,下图是得到的性能快照以及数据解析。
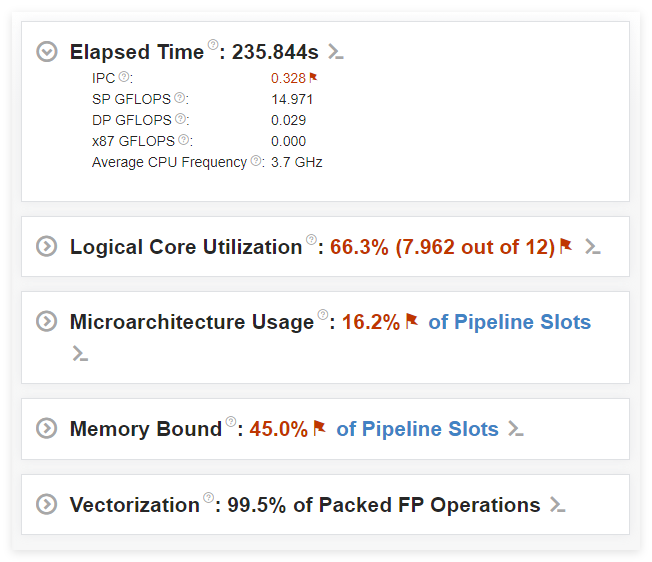
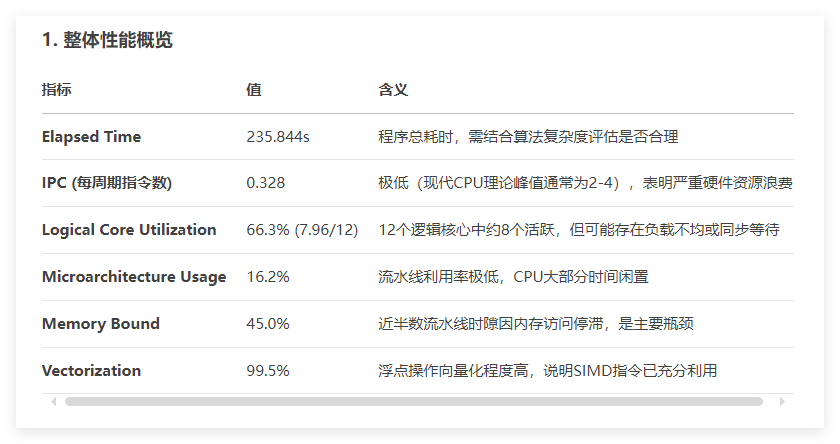
分析结果显示,除了Vectorization这一项,其他表现都很一般,Vectorization是向量化的意思,用于衡量程序利用CPU的SIMD(单指令多数据)指令集(如SSE、AVX、AVX-512)执行并行计算的效率,这一项几乎达到了100%,可以断定,Vectorization起到了决定性的作用,将Vectorization的各项展开如下:
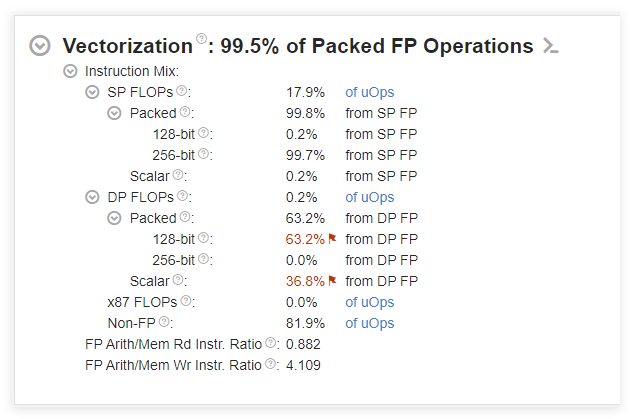
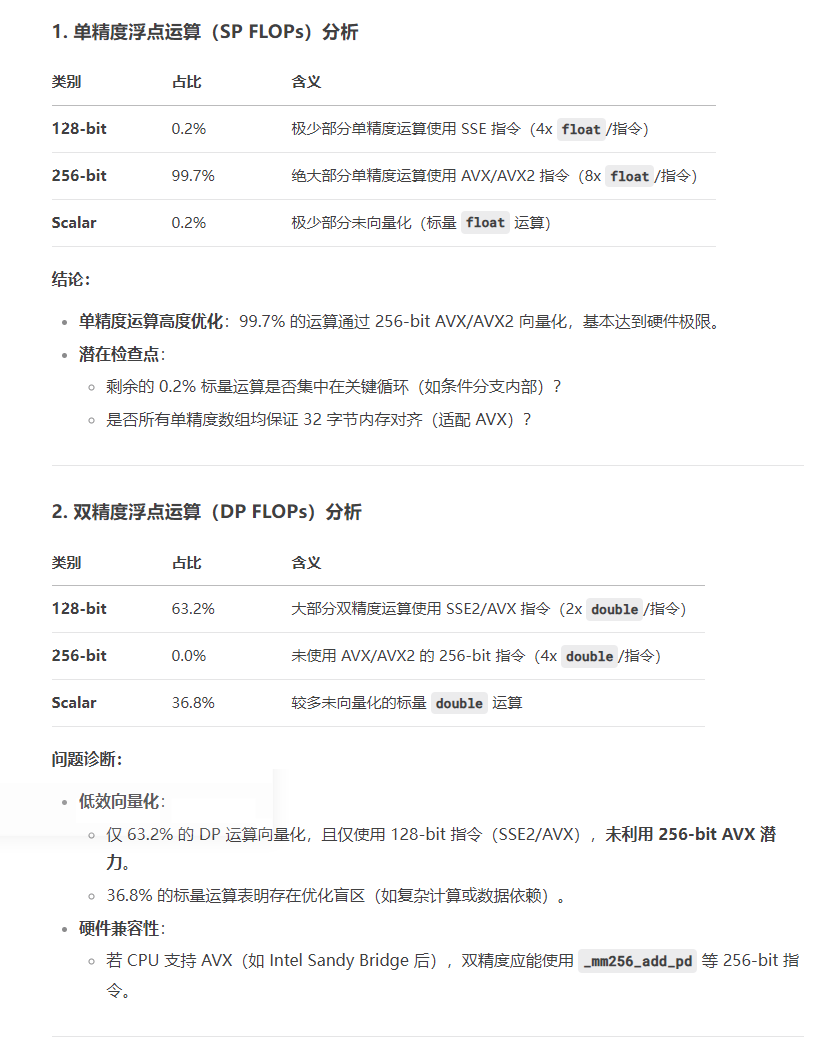
不难看出,halcon大量使用了256-bit的浮点运算,也就是AVX/AVX2指令集,其中单精度浮点运算的99.7%几乎到了极限,双精度浮点运算128-bit占比63.2%,其余则为标量运算(Scalar),占比36.8%。基于以上分析,我开始对自己的算法进行改进,第一步就是使用AVX/AVX2指令集,修改之后执行速度有了一定的提升,但是相比halcon还是有很大差距,后面我会继续优化。